gImageReader 简要介绍
gImageReader 简要介绍
在之前的文章中曾经提到过利用 CAJViewer 对 PDF 文件进行 OCR,但是这种做法有个比较大的问题,就是 CAJViewer 的 OCR 是需要手工去选择 OCR 范围的,不能自动的 OCR 全文。近期因为需要 OCR 一份有几十页的文件,不得不寻找替代方案,最终找到了 gImageReader。
Tesseract Open Source OCR Engine 是一个开源的 OCR 引擎(以下简称“Tesseract”),支持包括中文(简体)、中文(繁体)在内的多种文字的 OCR,具体的支持清单可以在 Data Files 上查看
gImageReader 是一个开源的基于 Tesseract Open Source OCR Engine 的跨平台的 GUI,
下载安装
在 gImageReader 项目的 Releases页 上下载对应的安装包,个人比较推荐基于 Tesseract 4.0的版本,OCR 的效率较3.0的版本高。
双击安装,没有捆绑,可以一直点下一步,但是有两个地方需要注意。
- 在 Choose Components 页面,选择 Standard (localized),否则安装完成之后是英文界面。
- 在 Choose Users 页面,选择 Install just for me,否则之后下载中文识别包时,需要以管理员权限运行 gImageReader。
下载中文识别包
- 安装完成后,在开始屏幕中启动 gImageReader,如果安装时没有选择错误,此时的界面应该是中文的,虽然有些地方汉化不完整。
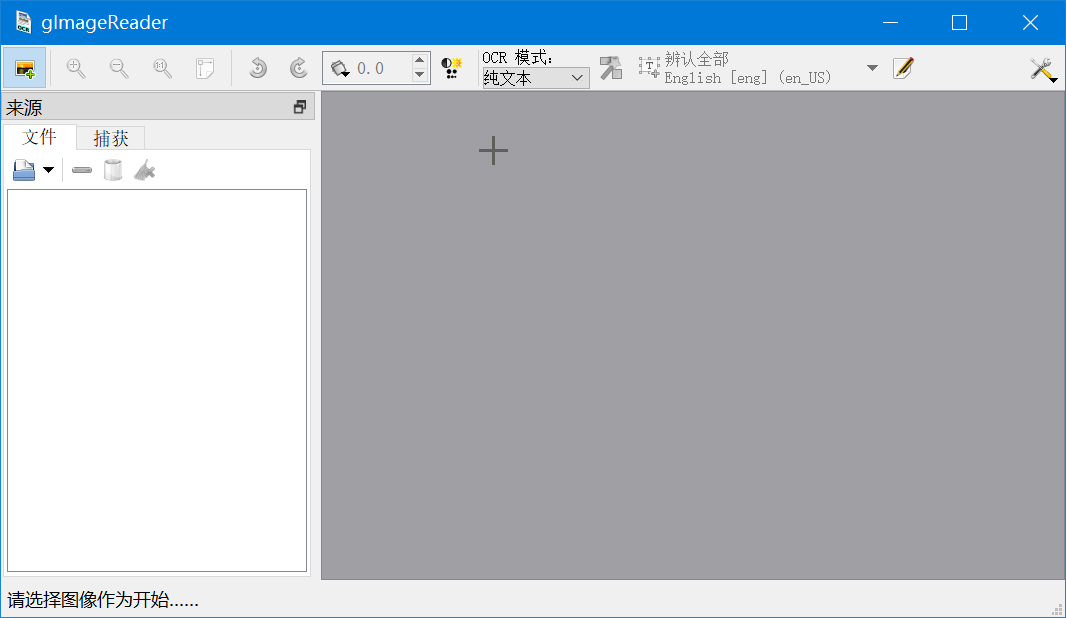
- 点击 gImageReader 右上角的设置按钮,选择 “管理语言”,在弹出的窗口中勾选需要OCR的语言,我选择的是“简体字”、“简体字 纵”、“繁体字”、“繁体字 纵”,然后点击“应用(Apply)”。gImageReader 会自动下载对应的语言识别包。
OCR 使用
- 在 gImageReader 中打开需要识别的 PDF 或图片文件,然后在上方选择你需要OCR的语言,点击辨认按钮,gImageReader 会自动开始 OCR,OCR 的结果就和文件的具体质量有关系,识别率我个人还是可以接受的。